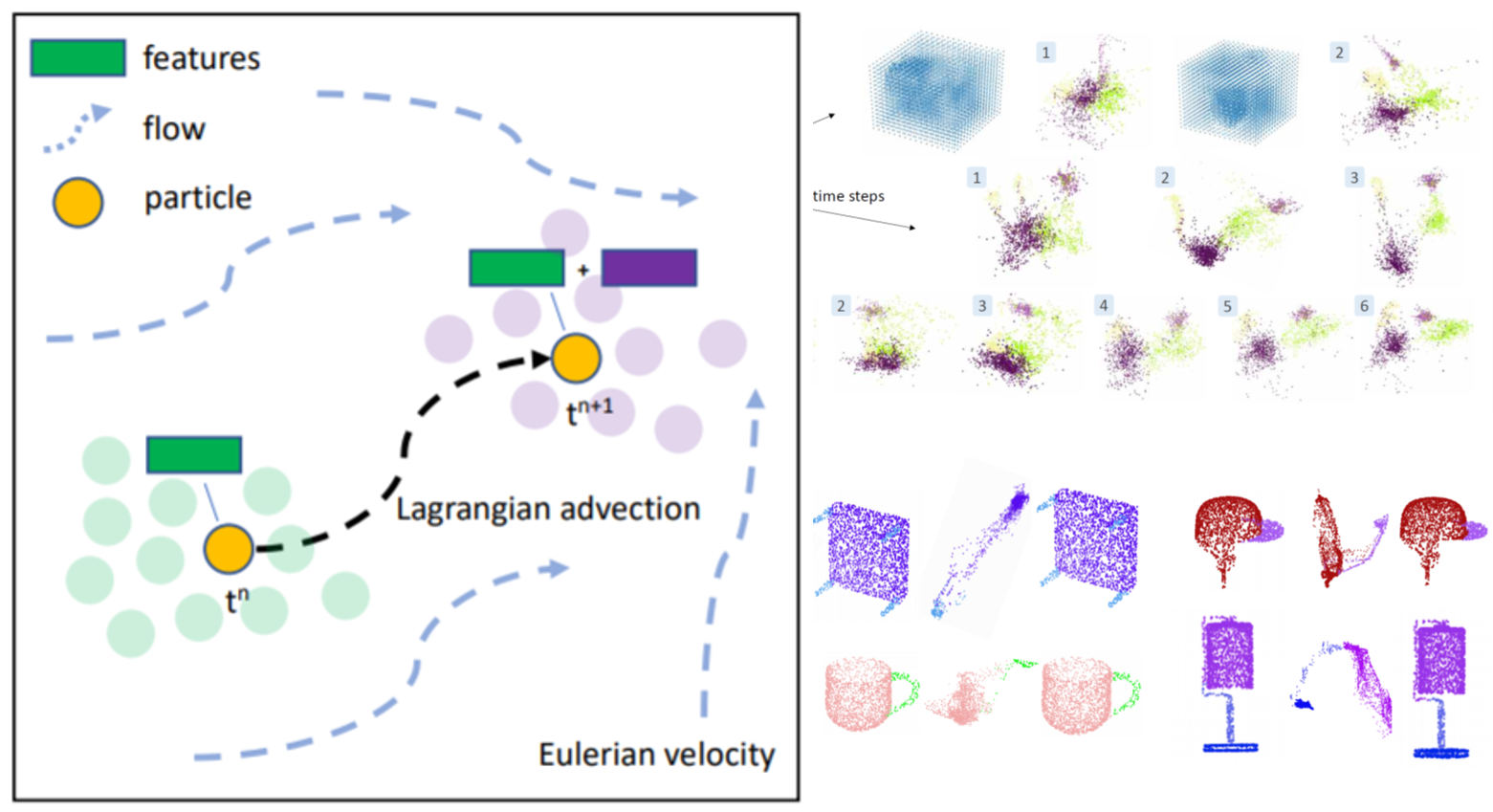
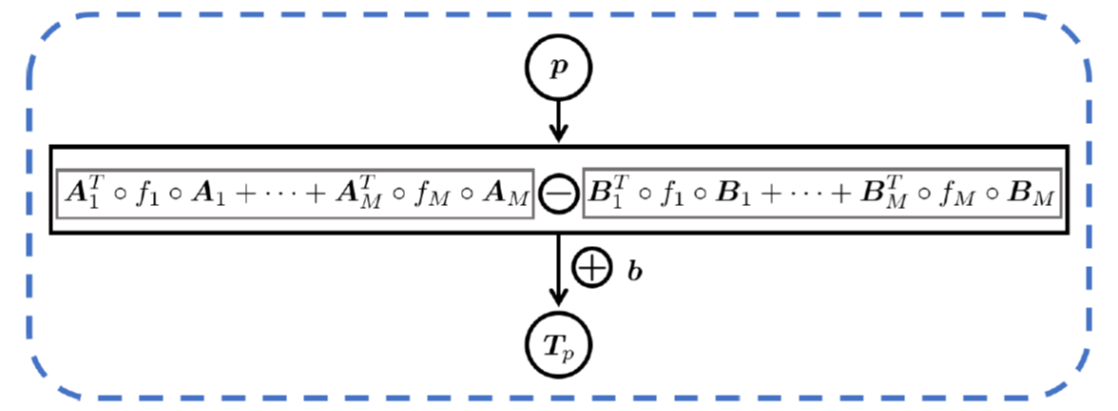
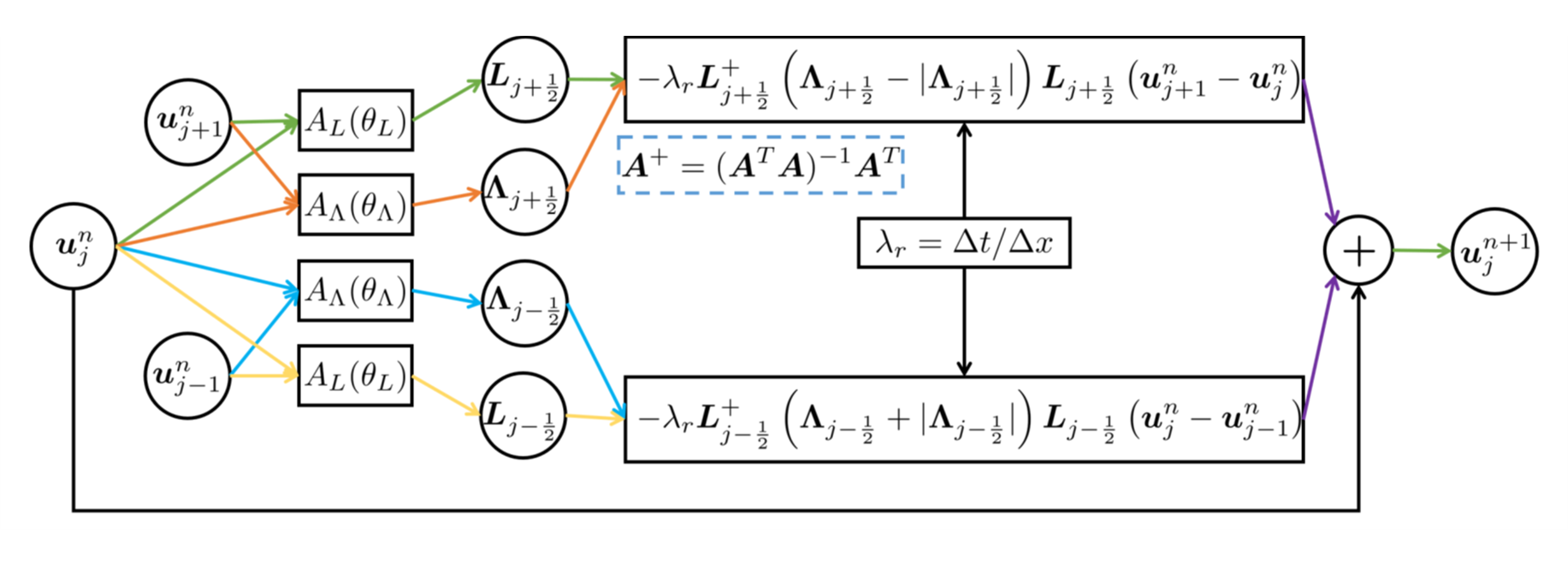
Foundational Generative Models for LipSync
A state-of-the-art lipsync generation stack from scratch, including highly compressed video VAEs and diffusion generators. The system improved audio-visual alignment, identity preservation, and fine facial dynamics across challenging poses. Example videos.